Repairing Spatial Data
When attempting to import GIS data into a SQL Server, there exist several constraints enforced on the data being loaded for integrity purposes. These constraints may generate error messages that prevent data from being exported properly. As part of Assetic’s database configuration, polygon data exported into the system is subject to similar rigorous standards to prevent the import of broken or ambiguous polygons which lack a coherent and clearly defined structure. Unfortunately, many WKT (Well Known Text) exporting extensions fail in meeting these standards, producing polygon datasets that are incompatible with Assetic’s database standards. As a workaround to ‘broken’ polygons, Assetic recommends running an automated repair method such as Prepair, PostGIS 2.0’s ST_MakeValid() function, or other such tools.
Using the Prepair Tool
The Prepair tool can be downloaded from the following link:
https://github.com/tudelft3d/prepair/releases/download/v0.7.1/prepair-x64-0.7.1.zip
The file should be downloaded and extracted into a folder of choice. The tool can be executed via the following set of steps:
Launch the Windows Command Shell\Command Prompt. This can be accessed by running ‘cmd’ from the start menu.
Navigate to the folder into which the contents of the Prepair folder were extracted. This can be achieved by running the command ‘cd <folder path>’, without the quotation marks, and where <folder path> is the file path to the folder containing the contents.
From here, typing in the command ‘prepair’ will give a quick overview of the module’s functionality:
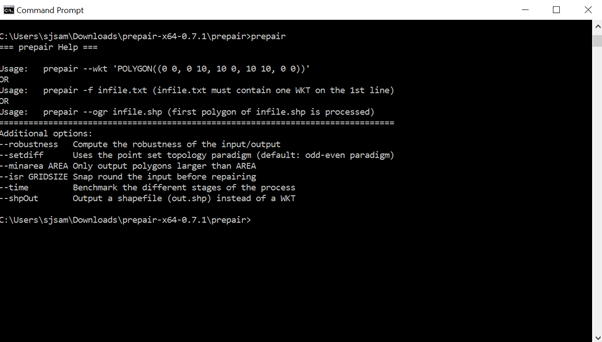
The whole suite of functionality is beyond the scope of this document. The focus of this article covers the ‘prepair –wkt’ option, which takes a Polygon input and performs shape correction to return a corrected Multipolygon output. To run it, the user runs the following command:
‘prepair –wkt “POLYGON” ‘, where POLYGON is simply the Polygon to be corrected.
Important: It is mandatory to encase the word polygon in double quotation marks.
A sample execution is provided below:
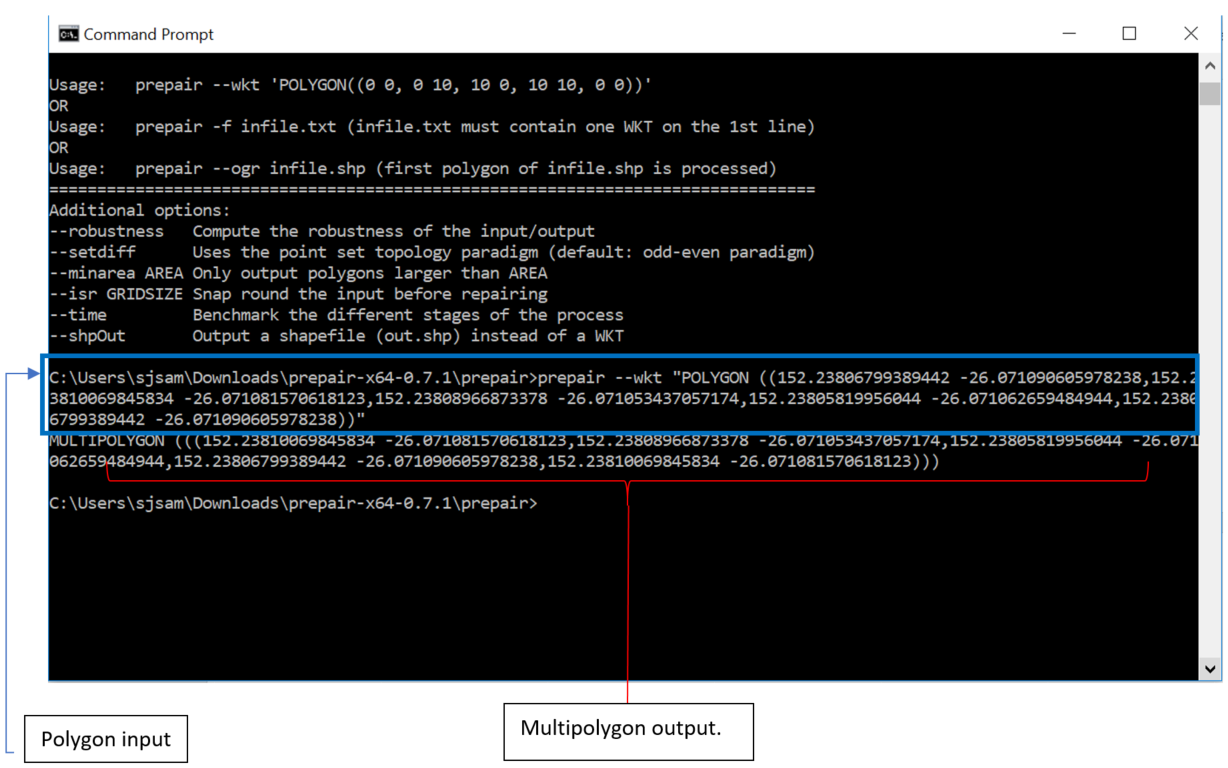
The Multipolygon output is suitable for directly exporting into Assetic’s systems.
Handling large polygons
On occasion, the need to process exceptionally large and intricate polygons may arise. Such polygon data is usually characterized by having many points at a high degree of measuring precision, leading to many coordinate points, with each coordinate point having many decimal points. The Windows PowerShell has an inherent limitation of inputs of up to 8191 characters, and in many cases, large polygons will quickly meet or exceed the input limitations. It is not always feasible or simple to truncate the data to be repaired. In such cases, the following set of procedures is the recommended workaround.
The Prepair tool has the functionality of repairing Polygon data from text files, which can be utilized to work around the PowerShell limitation.
Paste the polygon data into a text file and save it into the same location as the Prepair folder.
As can be observed in the screenshot, the quotation marks are unnecessary when loading polygon data through a .txt file.
Next, running the following command on the command line:
Prepair -f <TEXTFILE>, where <TEXTFILE> is the .txt file containing the target polygon data.
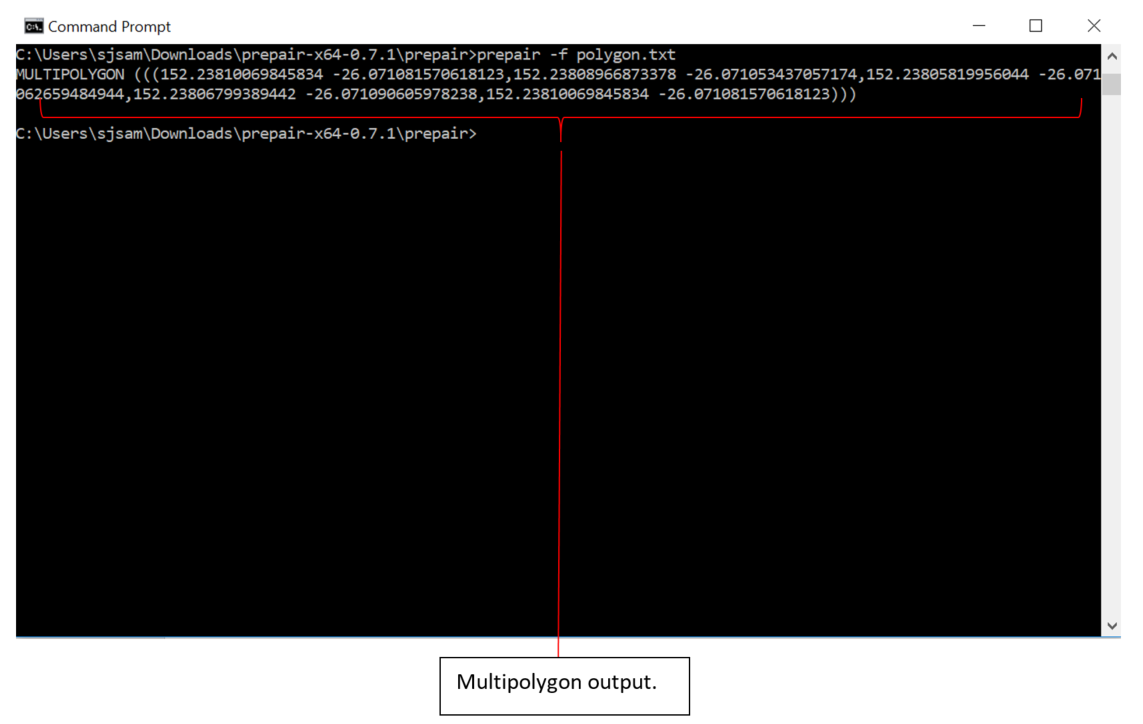
Please note that the above method only repairs one polygon per .txt file and so users should take care to avoid storing multiple lines of Polygons in the .txt file to attempt to bulk repair many polygons at once.
Bulk Repair Polygons
To perform a bulk repair of multiple polygons at once, a scripted approach is recommended. A sample script utilizing Python and the subprocess module is available as a reference below:
NOTE To learn more about the Python programming language, and for additional information on available Assetic Python packages, please see the Assetic Python SDK - Quick Start article.
This sample script parses an auto-generated error file (.csv) created by the Assetic Cloud Data Exchange if import errors occur during a spatial import. The repaired spatial data is appended to additional columns with the suffix "_Fixed" in the output file.
The sample script also assumes that the standard csv template for spatial imports from the Data Exchange Import Wizard (Mapping -> Asset Spatial) is being used. This is for the purposes of reading and parsing the error file data using the standard template column headers ("Asset ID", "Point", "Polygon", "Line").
If using the sample script the file paths found on lines 127, 130, and 131 must be modified. These paths point towards the directory of the extracted 'Prepair' tool, the input file path (.csv), and a nominated output file (.csv) file path.
NOTE If the output file is used for a subsequent Data Exchange import, care should be taken during the mapping steps of the Import Wizard to change the mapping to the new column containing the repaired spatial data.
- from subprocess import Popen, PIPE
- import pandas as pd
- import os
- import re
- """
- Assetic.BulkPrepair.py
- This script demonstrates how to repair broken spatial data in Well Known Text (WKT) format using the Prepair tool.
- The script parses the auto-generated error file (.csv) from the Assetic Cloud Data Exchange import:
- Mapping -> Asset Spatial
- Errors are filtered and repaired depending on the type of the WKT (i.e Polygons, Multi-Polygons and Linestrings).
- - Polygons and Multi-Polygons are repaired using the Prepair utility
- - Linestrings are attempted to be repaired by checking for consecutive duplicate Points
- The repaired data is then appended as new columns when saved to the .csv output file.
- Prepair download link: https://github.com/tudelft3d/prepair/releases
- Full documentation: https://assetic.zendesk.com/hc/en-us/articles/360000516615
- Author: Shien Jinn Sam (Assetic)
- """
- def repair_linestring(broken_linestrings):
- # isolate points from linestring in order to compare and remove consecutive duplicates
- fixed_linestrings = []
- for linestring in broken_linestrings:
- # find if linestring or multilinestring through WKT prefix
- wkt_prefix = str.split(linestring, "(")[0].strip()
- valid_prefix = ['LINESTRING', 'MULTILINESTRING']
- if wkt_prefix.upper() not in valid_prefix:
- raise ValueError(f"Invalid Line Prefix encountered: {wkt_prefix}.\n"
- f"Valid Values:{valid_prefix}")
- if wkt_prefix.upper() == 'MULTILINESTRING':
- # remove wkt prefix and strip enclosing outer parenthesis
- wkt_content = linestring[len(wkt_prefix):].strip()[1:-1]
- # split wkt on parentheses to get list of each line that comprises the multiline
- wkt_multilines_list = re.findall(r"\((.*?)\)", wkt_content)
- # parse each line individually to repair
- fixed_sub_lines = list()
- for line in wkt_multilines_list:
- # parse the line and remove repeated points
- parsed_line = _del_repeated_linestring_pnts(line)
- # put the linestring back inside parenthesis and append to list
- fixed_sub_lines.append("(" + parsed_line + ")")
- # put all lines from the multiline back into a single WKT string
- fixed_multiline = "MULTILINESTRING(" + str(", ".join(fixed_sub_lines)) + ")"
- fixed_linestrings.append(fixed_multiline)
- elif wkt_prefix.upper() == 'LINESTRING':
- # Remove leading "LineString" string and brackets for just comma separated points
- # Also Strip leading and trailing spaces, and separate each point into a list
- wkt_content = linestring[linestring.find("(") + 1:]
- wkt_content = wkt_content[0:wkt_content.find(")"):]
- parsed_line = _del_repeated_linestring_pnts(wkt_content)
- # reconstruct LINESTRING in valid WKT format
- fixed_linestrings.append("LINESTRING(" + parsed_line + ")")
- return fixed_linestrings
- def _del_repeated_linestring_pnts(wkt_string: str):
- """
- Accepts a WKT Linestring in a str format, and removes any vertices (points)
- that do not adhere to duplicate vertex rules.
- To adhere to OGC standards, the Linestring is split into individual points
- and the points are compared for duplicates. A well formatted Linestring
- will not have consecutive duplicate vertices (points), and will also not
- have overlapping segments where duplicate vertices with a single vertex is
- between them.
- """
- # seperate wkt string into a list of points for comparison
- raw_points_list = [item.strip() for item in wkt_string.split(',')]
- # Get total number of points, minus 1 to adjust for 0 index
- total_points = len(raw_points_list)
- # Skip linestrings with only 2 points, deleting 1 would make it no longer a Linestring
- if total_points <= 2:
- return wkt_string
- # Start from index 0 and iterate over full points list to check for vertex OGC compliance
- i = 0
- while i < (total_points - 1):
- if total_points < 2:
- print("Invalid LINESTRING detected! Repaired linestring is less than 2 vertices.")
- # check immediate neighbor duplicates
- if raw_points_list[i] == raw_points_list[i + 1]:
- del raw_points_list[i + 1]
- total_points -= 1
- # also move i iterator back 1 to allow regressive leapfrog check after change
- if i > 0:
- i -= 1
- continue
- # check for duplicate line segment, leapfrog 1 point and check if that point is duplicate
- lf = i + 2
- if lf <= (total_points - 1):
- if raw_points_list[i] == raw_points_list[lf]:
- del raw_points_list[lf]
- total_points -= 1
- continue
- # iterate and continue checks
- i += 1
- # join the points back to a str and return
- rejoined_points = ", ".join(raw_points_list)
- return rejoined_points
- def prepair_polygons(prepair_dir, broken_polygons):
- path = prepair_dir
- # initiate empty list for storing the fixed polygons
- outputs = []
- # create loop
- for polygon in broken_polygons:
- try:
- # defaults to using command line for repairing but also check the polygon isn't bigger than 32768 characters
- command = ['prepair', '--wkt', polygon]
- # collect output and error data as byte types
- process = Popen(command, cwd=path, shell=True, stdin=PIPE, stdout=PIPE, stderr=PIPE)
- out, err = process.communicate()
- except FileNotFoundError as e:
- # Command line limit on CreateProcess() function has 32768 char limit for args
- # Handle this and treat it as the command line is too long
- if len(polygon) >= 32768:
- out = None
- err = 'The command line is too long.'.encode(encoding='ascii')
- else:
- # unknown error not yet handled, rethrow
- raise e
- # If polygon is too large, create a .txt file for loading to overcome Windows command shell limitations.
- # This is computationally expensive, but for all practical purposes, it will run relatively quickly.
- # Only polygons>8191 characters/points will require this.
- if err.decode("ascii").strip() == 'The command line is too long.':
- # Write and load polygon from a .txt file to sidestep windows shell command character input limitation
- # The previous polygon will be overwritten in the next cycle of the for loop
- f = open(os.path.join(path, 'Polygon.txt'), 'w')
- f.write(polygon)
- f.close()
- # specify command line command
- command = ['prepair.exe', '-f', "polygon.txt"]
- # initiate child process
- process = Popen(command, cwd=path, shell=True, stdin=PIPE, stdout=PIPE, stderr=PIPE)
- out, err = process.communicate() # collect output and error data as byte types
- outputs.append(out.decode("ascii").strip()) # append decoded bytes and remove trailing whitespace
- return outputs
- def main(prepair_dir, input_file_path, output_file_path):
- # Read data from .csv error file into a pandas datatable
- errors = pd.read_csv(input_file_path, dtype=str)
- # create a list to hold the output dataframes
- fixed = list()
- # 1. Get Polygons/Multipolygons data and pass the 'Polygon' WKT column to Prepair
- broken_polygons = errors[~errors["Polygon"].isnull()].copy()
- polygons = broken_polygons["Polygon"]
- if not polygons.empty:
- fixed_polygons = prepair_polygons(prepair_dir, polygons)
- broken_polygons["Polygon_Fixed"] = fixed_polygons
- fixed.append(broken_polygons)
- # 2. Get Linestring and remove consecutive duplicate Points (common issue) MULTILINESTRING rows are not handled
- broken_linestring = errors[~errors["Line"].isnull()].copy()
- linestrings = broken_linestring["Line"]
- if not linestrings.empty:
- fixed_linestrings = repair_linestring(linestrings)
- broken_linestring["Line_Fixed"] = fixed_linestrings
- fixed.append(broken_linestring)
- data_out = pd.DataFrame()
- # if both Polygons and Lines have been repaired, merge the fixed data together
- if len(fixed) > 1:
- data_out = pd.concat(fixed)
- elif len(fixed) == 1:
- data_out = fixed[0]
- # Write to the output file
- if not data_out.empty:
- data_out.to_csv(output_file_path, index=False)
- else:
- print("Output pandas dataframe is empty. No data has been repaired.")
- # This will run the method main() to start the repair process
- # Please update the file paths below for your prepair directory and input/output files.
- if __name__ == "__main__":
- # Set prepair directory, download link @https://github.com/tudelft3d/prepair/releases
- prepair_directory = "D:/temp/prepair-x64-0.7.1"
- # Set paths here for the input and output CSV files
- input_file = "C:/temp/broken_data.csv"
- output_file = "C:/temp/fixed_data.csv"
- # Run the repair process
- main(prepair_dir=prepair_directory,
- input_file_path=input_file,
- output_file_path=output_file)
